Email / X / Github / Scholar / LinkedIn / CV
I am a Research Scientist at Netflix on Creative Tech, led by Jian Ren. We work on video generation for filmmaking.
I completed my Ph.D. at the University of Toronto, and was previously part of Paul Debevec's team at Eyeline.

|

Kuan Heng Lin, Zhizheng Liu, Pablo Salamanca, Yash Kant, Ryan Burgert, Yuancheng Xu, Koichi Namekata, Yiwei Zhao, Bolei Zhou, Micah Goldblum, Paul Debevec, Ning Yu
CVPR, 2026 (Highlight)
arXiv / code / project page
Vista4D reshoots a dynamic scene from a single source video along novel camera trajectories and viewpoints, by grounding the video and target cameras in a 4D point cloud!
It is robust to real-world 4D reconstruction artifacts, and generalizes to dynamic scene expansion and 4D scene recomposition!

Koichi Namekata, Yash Kant†, Zhizheng Liu, Ryan Burgert, Yuancheng Xu, Kuan Heng Lin, Emmett Steven, Julien Philip, Li Ma, Andrea Vedaldi, Paul Debevec, Ning Yu†
SIGGRAPH, 2026 (†equal supervision)
arXiv / code / project page
Go-with-the-Track unifies video compositing and motion control by conditioning a video diffusion model on multiple reference images and reference-anchored point tracks!
A single model handles keypoint-driven compositing, multi-reference camera control, and restylization, with point tracks establishing correspondences across generated frames!

Yash Kant, Ethan Weber, Jin Kyu Kim, Rawal Khirodkar, Su Zhaoen, Julieta Martinez, Igor Gilitschenski*, Shunsuke Saito*, Timur Bagautdinov*
CVPR, 2025 (Highlight)
arXiv / code / project page / tweets [explainer & attention-biasing]
We trained a high-resolution (1K) multi-view human generator on 3B human images and 2.5K studio captures!
Pippo outperforms all previous multiview methods! :)

Chen Guo*, Junxuan Li*, Yash Kant, Yaser Sheikh, Shunsuke Saito, Chen Cao
CVPR, 2025
arXiv / project page
Vid2Avatar-Pro creates photorealistic and animatable 3D human avatars from monocular videos!

Ethan Weber, Norman Müller, Yash Kant, Vasu Agrawal, Michael Zollhöfer, Angjoo Kanazawa, Christian Richardt
3DV, 2026
arXiv / code / project page
Fillerbuster auto-completes missing regions in casually captured shot with a multi-view diffusion model!

Koichi Namekata, Sherwin Bahmani, Ziyi Wu, Yash Kant, Igor Gilitschenski, David B. Lindell
ICLR, 2025
arXiv / code / project page
SG-I2V enables zero-shot image animations relying solely on the knowledge present in a pre-trained image-to-video diffusion model!

Yash Kant, Ziyi Wu, Michael Vasilkovsky, Gordon Qian, Jian Ren, Riza Alp Guler, Bernard Ghanem, Sergey Tulyakov*, Igor Gilitschenski*, Aliaksandr Siarohin*
CVPR, 2024
arXiv / code / project page / news [hackernews]
We trained a spatially aware multi-view diffusion model that can generate many consistent novel views in a single forward pass given a text prompt / image!
SPAD outperforms MVDream and SyncDreamer, and enables generating 3D assets from text within 10 seconds!
Derek Tam*, Yash Kant*, Brian Lester*, Igor Gilitschenski, Colin Raffel
TMLR, 2026
arXiv / code
We systematically evaluate several model merging methods within a unified experimental framework, focusing on compositional generalization.
We explore the impact of scaling the number of merged models and sensitivity to hyper-parameters, offering a clear assessment of the current state of model merging techniques.

Yash Kant, Aliaksandr Siarohin, Michael Vasilkovsky, Riza Alp Guler, Jian Ren, Sergey Tulyakov, Igor Gilitschenski
SIGGRAPH Asia, 2023
arXiv / project page
We perform novel view synthesis from a single image by repurposing Stable Diffusion inpainting model, and depth based 3D unprojection. We outperform baselines (such Zero-1-to-3) on PSNR and LPIPS metrics.
Our 3D-aware inpainting model was trained on Objaverse on 96 A100 GPUs for two weeks!
Yash Kant, Aliaksandr Siarohin, Riza Alp Guler, Menglei Chai, Jian Ren, Sergey Tulyakov, Igor Gilitschenski
CVPR, 2023
arXiv / project page
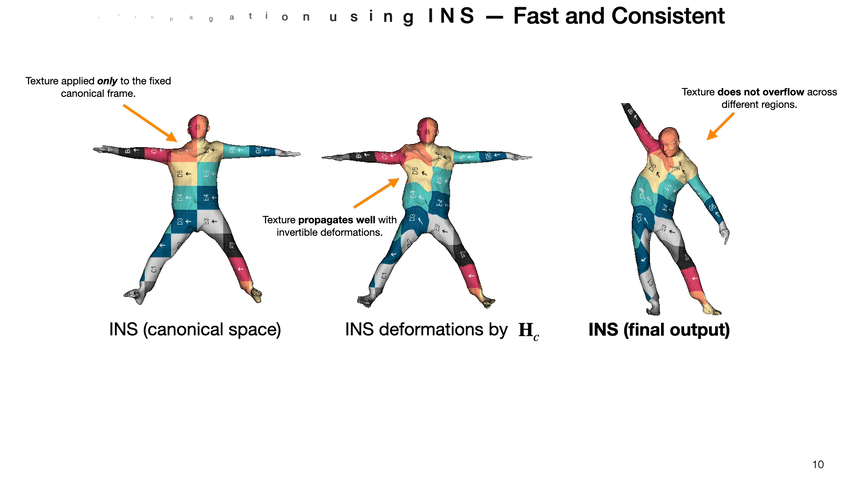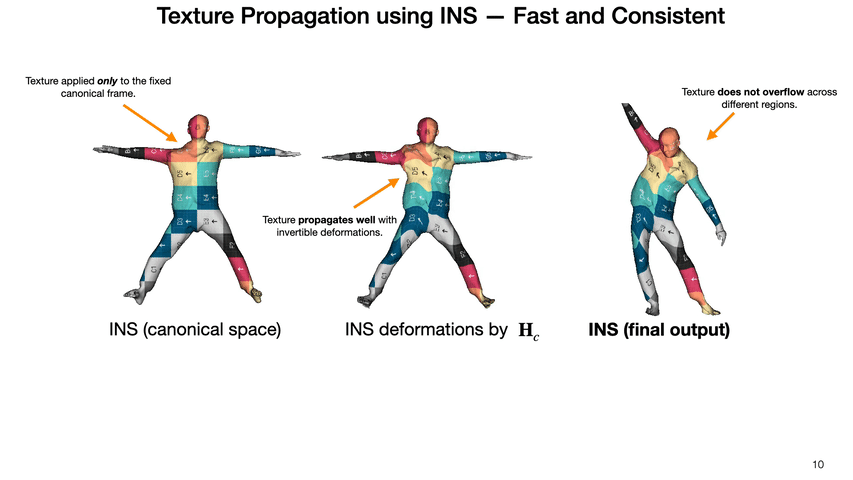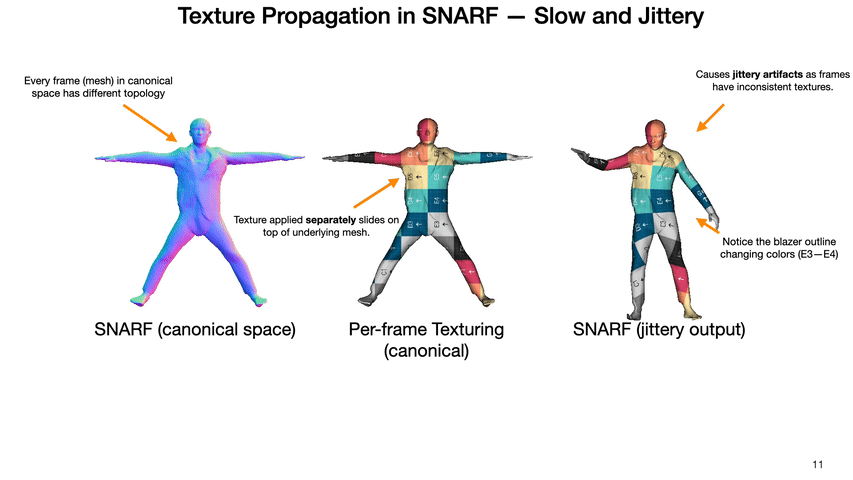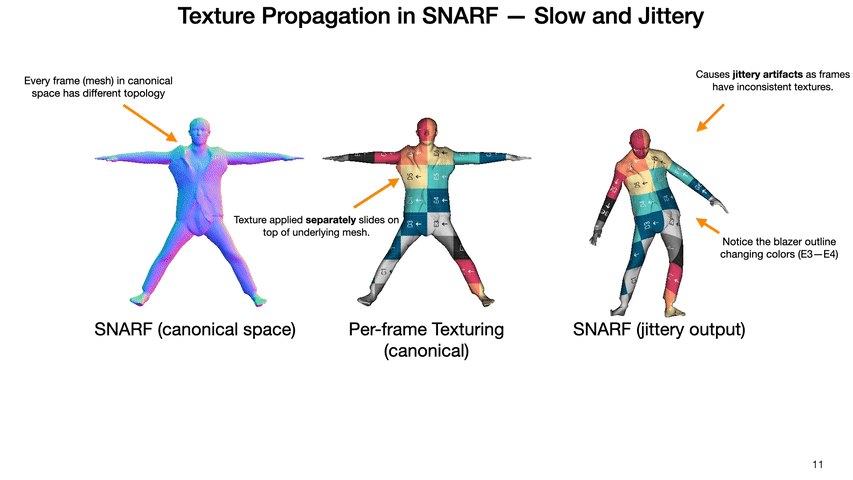
We propose an end-to-end invertible and learnable reposing pipeline that allows animating implicit surfaces with intricate pose-varying effects. We outperform the state-of-the-art reposing techniques on clothed humans while preserving surface correspondences and being order of magnitude faster!
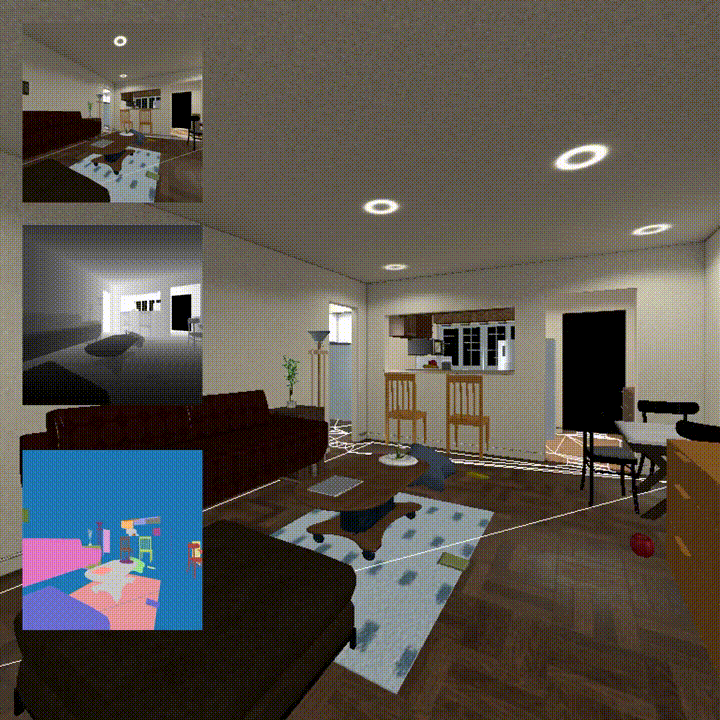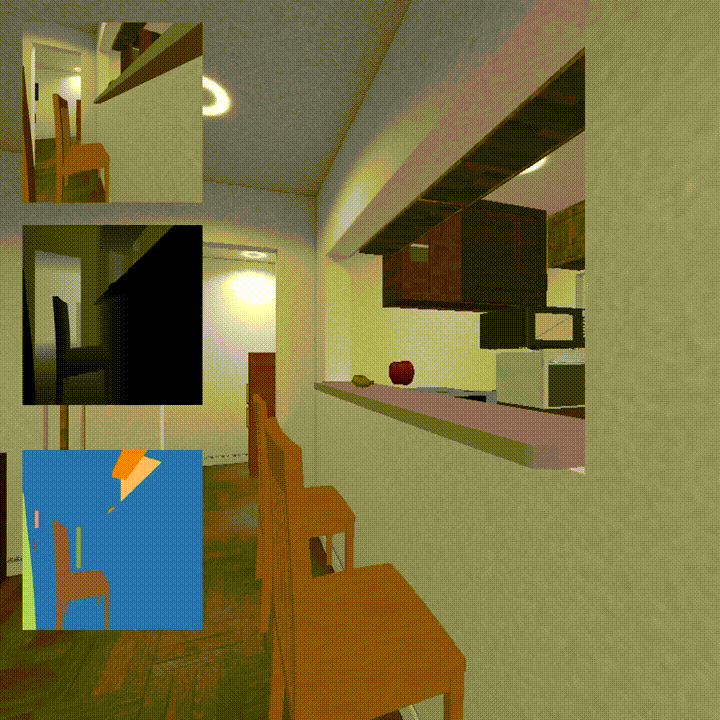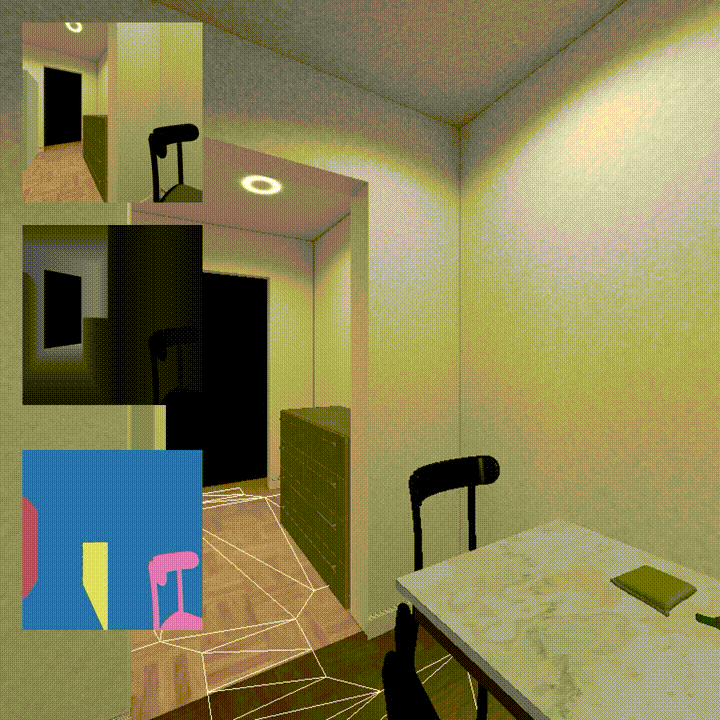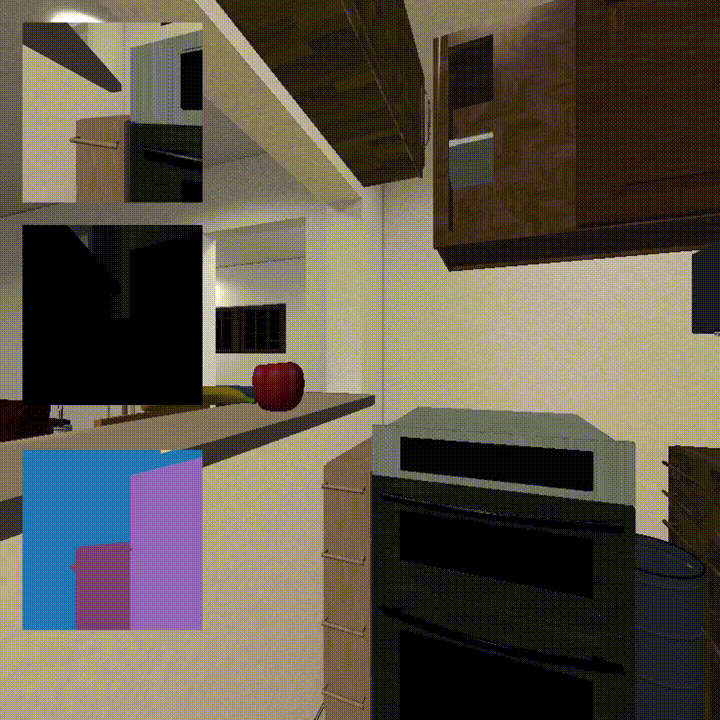
Yash Kant, Arun Ramachandran, Sriram Yenamandra, Igor Gilitschenski, Dhruv Batra, Andrew Szot*, and Harsh Agrawal*
ECCV, 2022
arXiv / project page / code / colab / news [coc-gt, tech-org]
Housekeep is a benchmark to evaluate commonsense reasoning in the home for embodied AI. Here, an embodied agent must tidy a house by rearranging misplaced objects without explicit instructions.
To capture the rich diversity of real world scenarios, we support cluttering environments with ~1800 everyday 3D object models spread across ~270 categories!

Ashkan Mirzaei, Yash Kant, Jonathan Kelly, and Igor Gilitschenski
ECCV, 2022
arXiv / code
We build a simple method to extract an object from a scene given 2D images, camera poses, a natural language description of the object, and a few annotated pixels of object and background.

Aniket Agarwal^, Alex Zhang^, Karthik Narasimhan, Igor Gilitschenski, Vishvak Murahari*, Yash Kant*
arXiv / project page / code
We introduce an automated Annotation and Video Stream Alignment Pipeline (abbreviated ASAP) for aligning unlabeled videos of four different sports (Cricket, Football, Basketball, and American Football) with their corresponding dense annotations (commentary) freely available on the web. Our human studies indicate that ASAP can align videos and annotations with high fidelity, precision, and speed!
Yash Kant, Abhinav Moudgil, Dhruv Batra, Devi Parikh, Harsh Agrawal
ICCV, 2021
arXiv / project page / code / slides
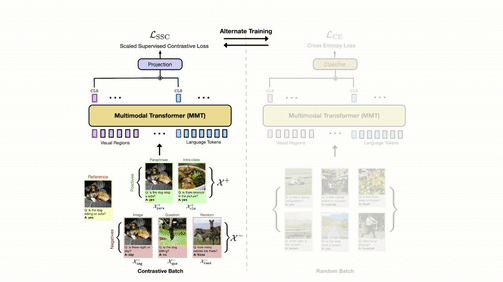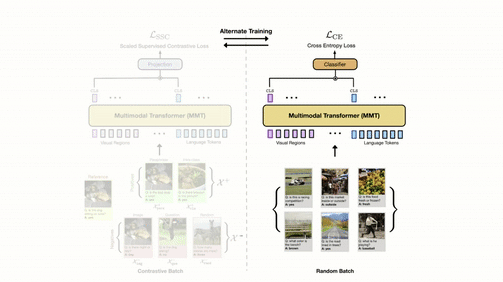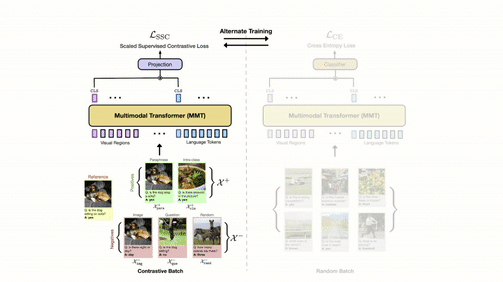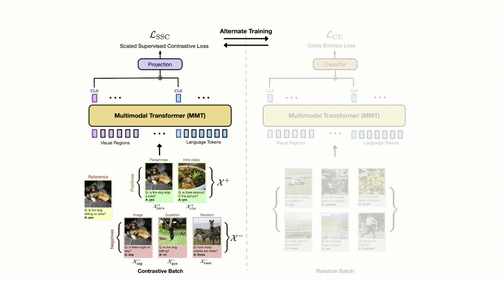
We propose a training scheme which steers VQA models towards answering paraphrased questions consistently, and we ended up beating previous baselines by an absolute 5.8% on consistency metrics without any performance drop!

Yash Kant, Dhruv Batra, Peter Anderson, Jiasen Lu, Alexander Schwing, Devi Parikh, Harsh Agrawal
ECCV, 2020
arXiv / project page / code / short talk / long talk / slides
We built a self-attention module to reason over spatial graphs in images. We ended up with an absolute performance improvement of more than 4% on two TextVQA bechmarks!
|
Borrowed and Modified from Jon Barron. |