|
|
|
|
|
|
|
|
|
|
|
|
| Published at ICCV, 2021 | ||
|
|
|
|
|
|
|
|
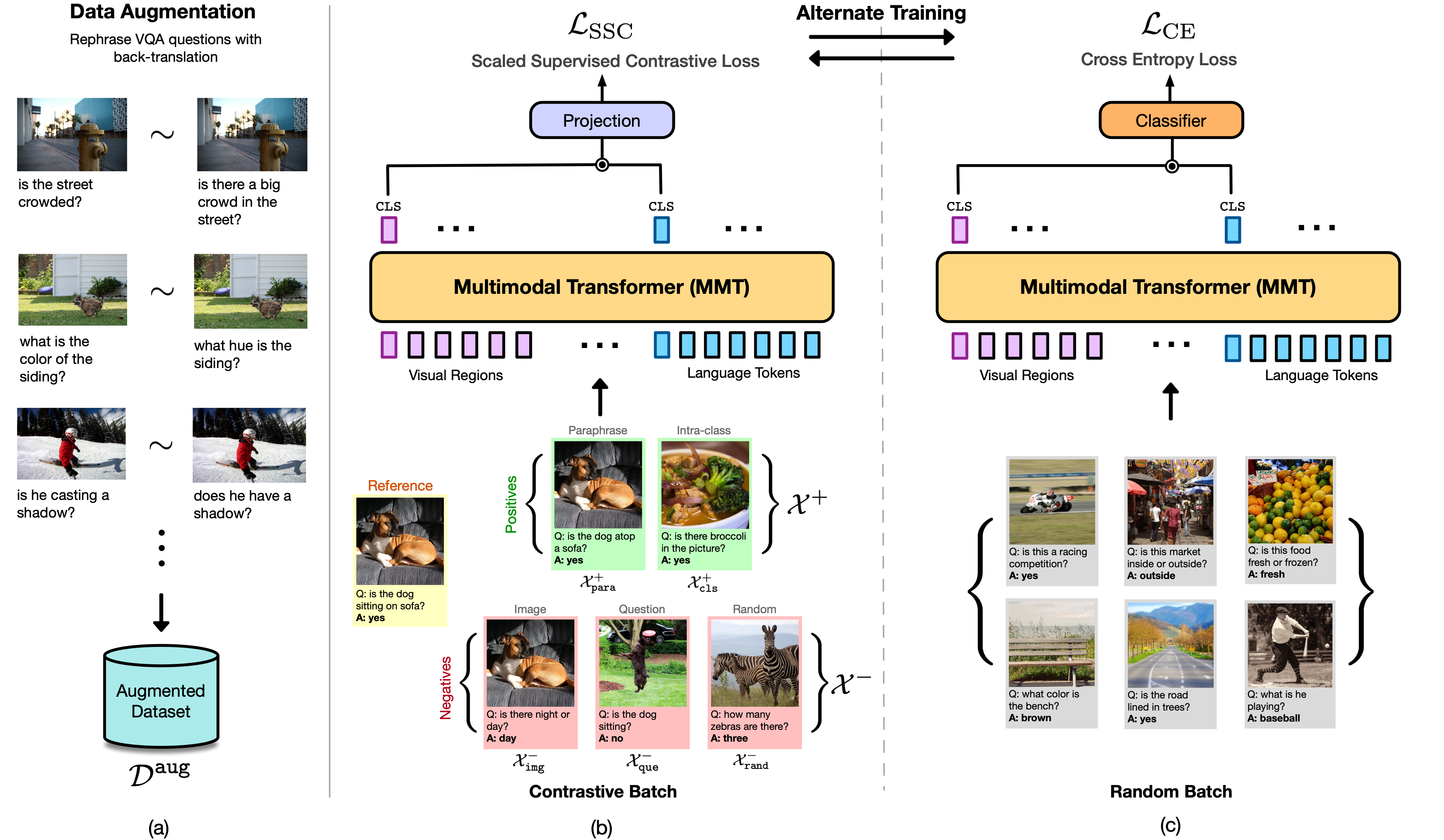
| Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage augmented data, we build on the recent success in contrastive learning. We propose a novel training paradigm (ConClaT) that optimizes both cross-entropy and contrastive losses. The contrastive loss encourages representations to be robust to linguistic variations in questions while the cross-entropy loss preserves the discriminative power of representations for answer prediction. We find that optimizing both losses -- either alternately or jointly -- is key to effective training. On the VQA-Rephrasings benchmark, which measures the VQA model's answer consistency across human paraphrases of a question, ConClaT improves Consensus Score by 1 .63% over an improved baseline. In addition, on the standard VQA 2.0 benchmark, we improve the VQA accuracy by 0.78% overall. We also show that ConClaT is agnostic to the type of data-augmentation strategy used. |

|
Citation
@inproceedings{kant2020spatially,
title={Contrast and Classify: Training Robust VQA Models},
author={Yash Kant and Abhinav Moudgil and Dhruv Batra
and Devi Parikh and Harsh Agrawal},
year={2021},
eprint={2010.06087},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
AcknowledgementsThis template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |