We introduce Housekeep, a benchmark to evaluate commonsense reasoning in the home for embodied AI. In Housekeep, an embodied agent must tidy a house by rearranging misplaced objects without explicit instructions specifying which objects need to be rearranged. Instead, the agent must learn from and is evaluated against human preferences of which objects belong where in a tidy house. Specifically, we collect a dataset of where humans typically place objects in tidy and untidy houses constituting 1799 objects, 268 object categories, 585 placements, and 105 rooms.
Next, we propose a modular baseline approach for Housekeep that integrates planning, exploration, and navigation. It leverages a fine-tuned large language model (LLM) trained on an internet text corpus for effective planning. We show that our baseline agent generalizes to rearranging unseen objects in unknown environments.
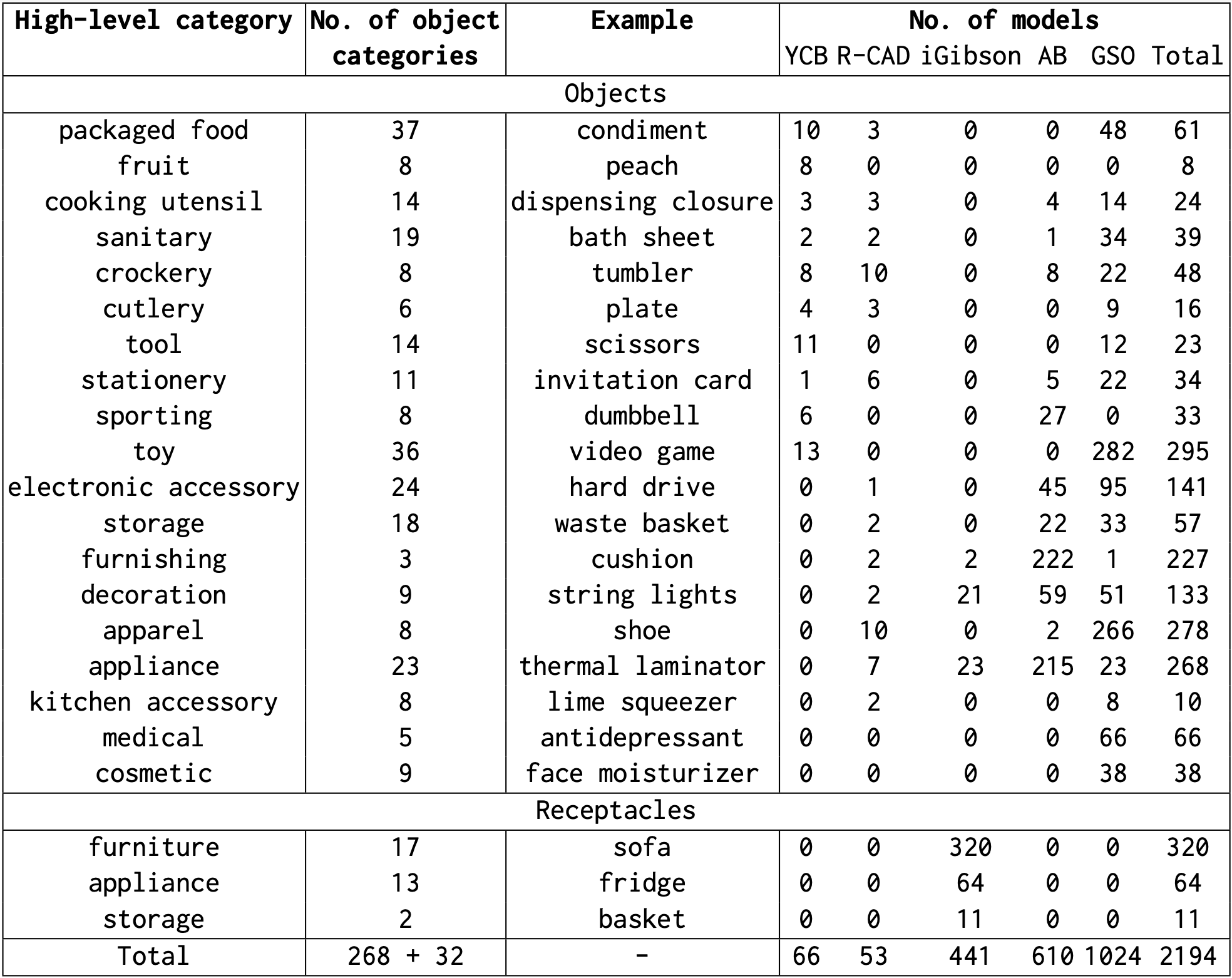 This table gives the number of object and receptacle models obtained from different sources.
This table gives the number of object and receptacle models obtained from different sources.