|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Published at ECCV, 2020 | ||||
|
|
|
|
|
|
|
|
|
|
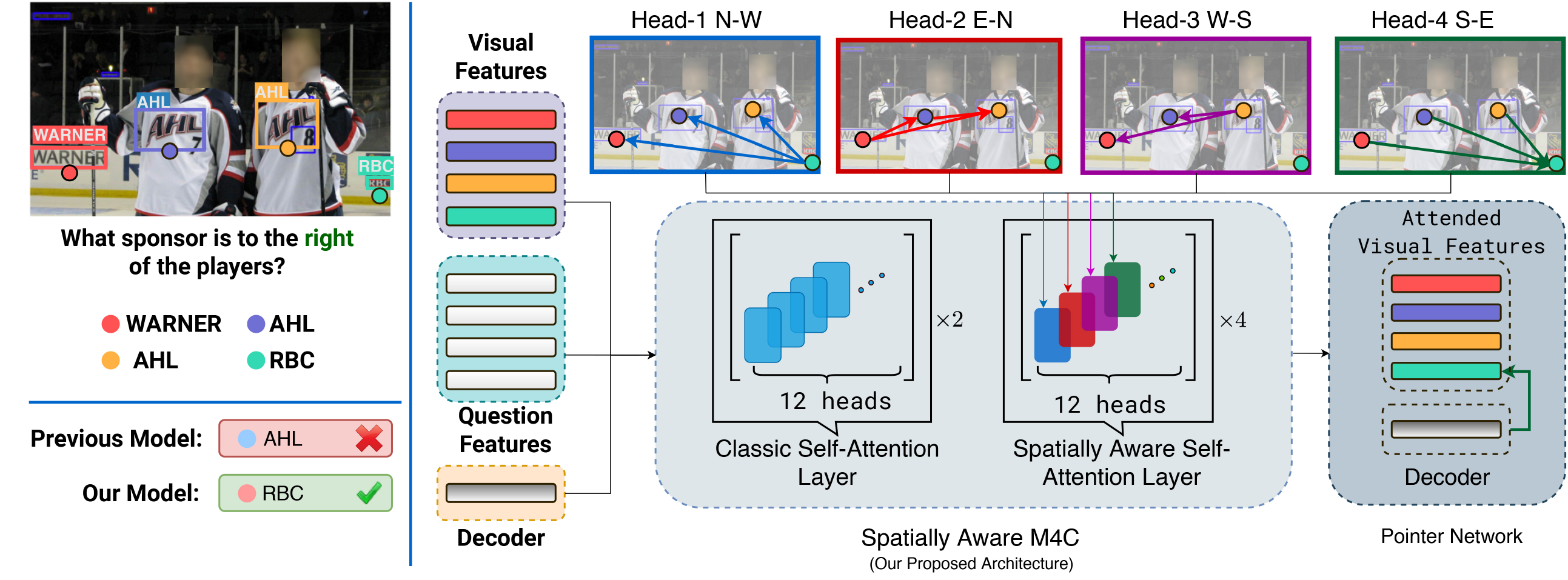
| Textual cues are essential for everyday tasks like buying groceries and using public transport. To develop this assistive technology, we study the TextVQA task, i.e., reasoning about text in images to answer a question. Existing approaches are limited in their use of spatial relations and rely on fully-connected transformer-like architectures to implicitly learn the spatial structure of a scene. In contrast, we propose a novel spatially aware self-attention layer such that each visual entity only looks at neighboring entities defined by a spatial graph. Further, each head in our multi-head self-attention layer focuses on a different subset of relations. Our approach has two advantages: (1) each head considers local context instead of dispersing the attention amongst all visual entities; (2) we avoid learning redundant features. We show that our model improves the absolute accuracy of current state-of-the-art methods on TextVQA by 2.2% overall over an improved baseline, and 4.62% on questions that involve spatial reasoning and can be answered correctly using OCR tokens. Similarly on ST-VQA, we improve the absolute accuracy by 4.2%. We further show that spatially aware self-attention improves visual grounding. |
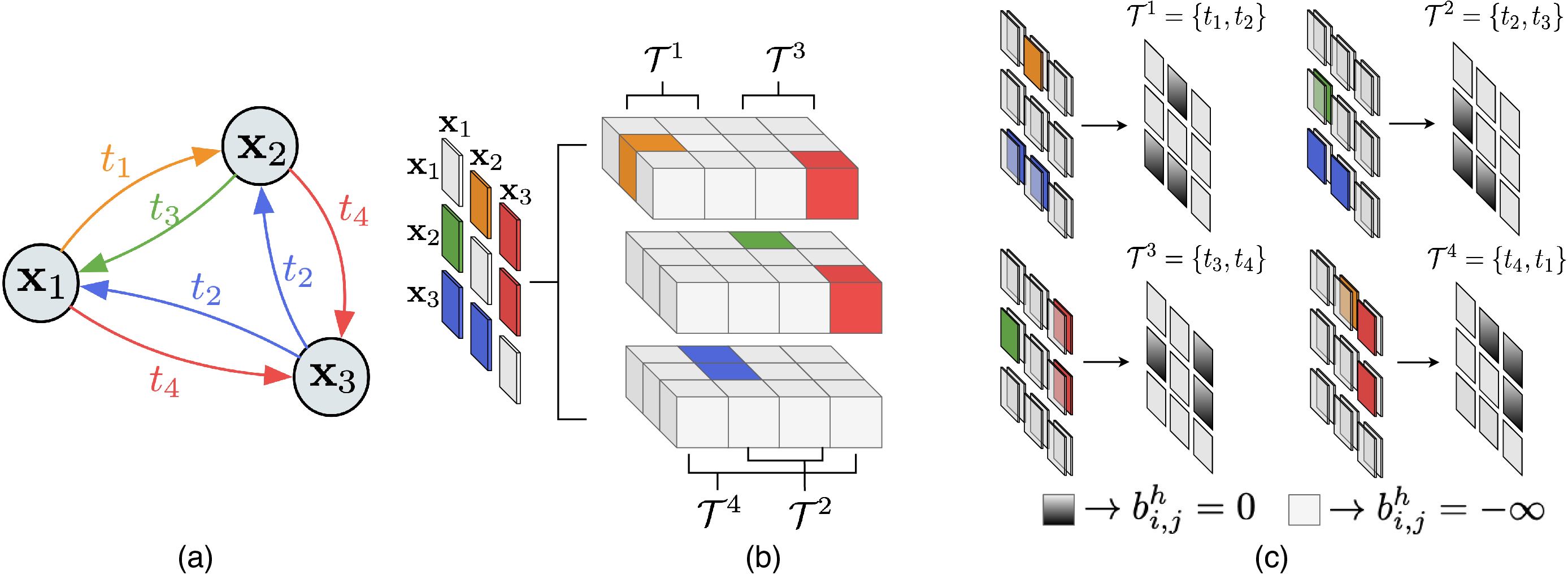
| We extend the vanilla self-attention layer to utilize a graph over the input tokens. Instead of looking at the entire global context, an entity attends to just the neighboring entities as defined by a relationship graph. Moreover, heads consider different types of relations which encodes different context and avoids learning redundant features. We define the heterogeneous graph over tokens from multiple modalities which are connected by different edge types. While our framework is general and easily extensible to other tasks, we present our approach for the TextVQA task. |
|
|
|

|
|
|

|
Citation
@inproceedings{kant2020spatially,
title={Spatially Aware Multimodal Transformers for TextVQA},
author={Kant, Yash and Batra, Dhruv and Anderson, Peter
and Schwing, Alexander and Parikh, Devi and Lu, Jiasen
and Agrawal, Harsh},
booktitle={ECCV}
year={2020}}
|
AcknowledgementsThis template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |